Ollama: Run AI Models Locally
Ollama is a powerful framework that enables users to run large language models (LLMs) locally on their machines, eliminating the need for cloud-based APIs.
🔹 Why Use Ollama?
- Free & Private: No reliance on external servers.
- Fast: Eliminates network delays.
- Offline Functionality: Works without an internet connection.
🔹 Example Command:
ollama run deepseek-r1:1.5b
This command runs DeepSeek R1 locally on your system.
LangChain: AI-Powered Application Framework
LangChain is a versatile framework that integrates LLMs with various data sources, APIs, and memory management tools, enabling seamless AI-powered application development.
🔹 Why Use LangChain?
- Connects LLMs to real-world applications.
- Facilitates chatbots, document analysis, and retrieval-augmented generation (RAG).
RAG: Retrieval-Augmented Generation
RAG is an AI method that enhances responses by retrieving relevant external data before generating answers, improving accuracy and minimizing hallucinations.
Example Use Case:
A PDF Q&A system that fetches relevant document content before generating responses.
DeepSeek R1: Advanced Local AI Model
DeepSeek R1 is an open-source AI model optimized for logical reasoning, problem-solving, and factual retrieval.
Why Use DeepSeek R1?
- Strong logical capabilities.
- Optimized for RAG applications.
- Can be run locally with Ollama.
How Do They Work Together?
- Ollama runs DeepSeek R1 locally.
- LangChain connects the AI model to external data.
- RAG retrieves relevant data to enhance AI responses.
- DeepSeek R1 generates accurate answers.
Example:
A Q&A system where users upload a PDF and ask questions about its contents—powered by DeepSeek R1 + RAG + LangChain on Ollama.
Why Run DeepSeek R1 Locally?
| Benefit | Cloud-Based Models | Local DeepSeek R1 |
|---|---|---|
| Privacy | ❌ Data sent to servers | ✅ 100% Local & Secure |
| Speed | ⏳ API latency | ⚡ Instant inference |
| Cost | 💰 Pay per API request | 🆓 Free after setup |
| Customization | ❌ Limited tuning | ✅ Full control |
| Deployment | 🌍 Cloud-dependent | 🔥 Works offline |
Step 1: Install Ollama
🔹 Download Ollama
- Visit the Ollama official site.
- Select your OS (macOS, Linux, Windows).
- Click Download and follow the installation steps.
Step 2: Running DeepSeek R1 on Ollama
🔹 Pull the Model
ollama pull deepseek-r1:1.5b
This downloads and sets up the DeepSeek R1 model.
🔹 Run DeepSeek R1
ollama run deepseek-r1:1.5b
This initializes the model, allowing you to interact with it.
Step 3: Setting Up a RAG System with Streamlit
🔹 Prerequisites
Ensure you have Python, a Conda environment (recommended), and required dependencies:
pip install -U langchain langchain-community streamlit pdfplumber semantic-chunkers open-text-embeddings faiss ollama prompt-template langchain_experimental sentence-transformers faiss-cpu
Step 4: Running the RAG System
🔹 Create a New Project
mkdir rag-system && cd rag-system
🔹 Create a Python Script (app.py)
import streamlit as st
from langchain_community.document_loaders import PDFPlumberLoader
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.llms import Ollama
from langchain.prompts import PromptTemplate
from langchain.chains.llm import LLMChain
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
from langchain.chains import RetrievalQA
st.title("📄 RAG System with DeepSeek R1 & Ollama")
uploaded_file = st.file_uploader("Upload your PDF file here", type="pdf")
if uploaded_file:
with open("temp.pdf", "wb") as f:
f.write(uploaded_file.getvalue())
loader = PDFPlumberLoader("temp.pdf")
docs = loader.load()
text_splitter = SemanticChunker(HuggingFaceEmbeddings())
documents = text_splitter.split_documents(docs)
embedder = HuggingFaceEmbeddings()
vector = FAISS.from_documents(documents, embedder)
retriever = vector.as_retriever(search_type="similarity", search_kwargs={"k": 3})
llm = Ollama(model="deepseek-r1:1.5b")
prompt = """
Use the following context to answer the question.
Context: {context}
Question: {question}
Answer:"""
QA_PROMPT = PromptTemplate.from_template(prompt)
llm_chain = LLMChain(llm=llm, prompt=QA_PROMPT)
combine_documents_chain = StuffDocumentsChain(llm_chain=llm_chain, document_variable_name="context")
qa = RetrievalQA(combine_documents_chain=combine_documents_chain, retriever=retriever)
user_input = st.text_input("Ask a question about your document:")
if user_input:
response = qa(user_input)["result"]
st.write("**Response:**")
st.write(response)
Step 5: Running the App
Start your Streamlit app:
streamlit run app.py
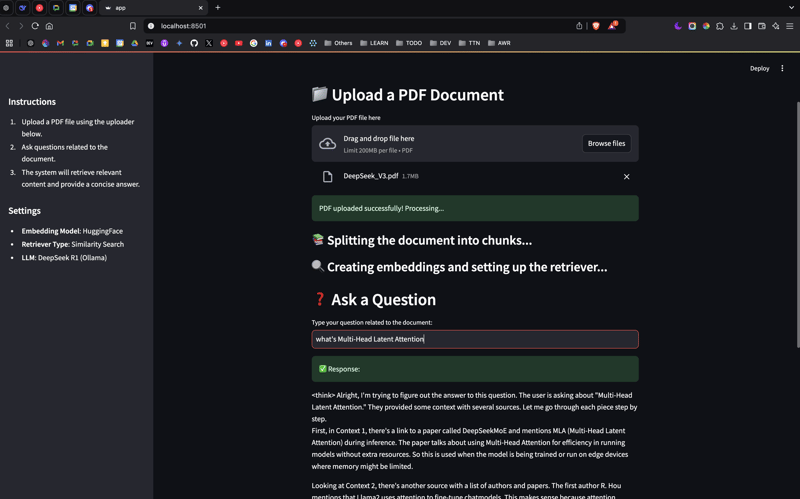
Final Thoughts
Successfully set up Ollama and DeepSeek R1!
Built a local RAG system for AI-powered document analysis.
Upload PDFs and ask AI-generated questions dynamically.